









")












 Tokens Playing This P2E Game")

Cardano has a complex architecture, and the project is getting implemented in multiple phases. Most of us have a very basic understanding of Cardano.
At the Cardano Shelley Summit 2020, we got an opportunity to get a 360-degree overview of Cardano from Duncun Cuotts, Technical Architect, IOHK.
Note: This is a semi-technical article, an excerpt from Duncun Cuotts’ own words.
Cardano Components
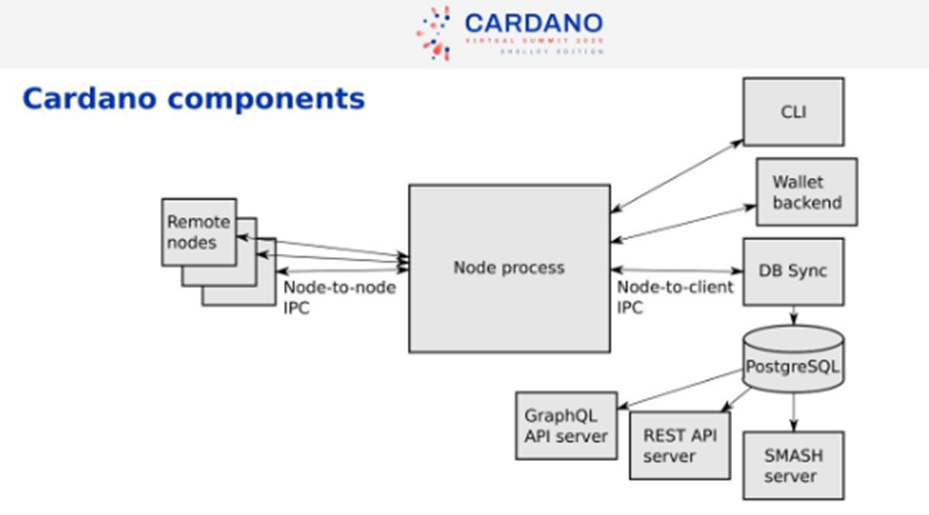
Node Process is the central system that communicates with other node processes across the internet. Daedelus is the wallet backend. The DB Sync component synchronizes the blockchain data into an SQL database. Then you can do multiple things with that data.
Inside a Node
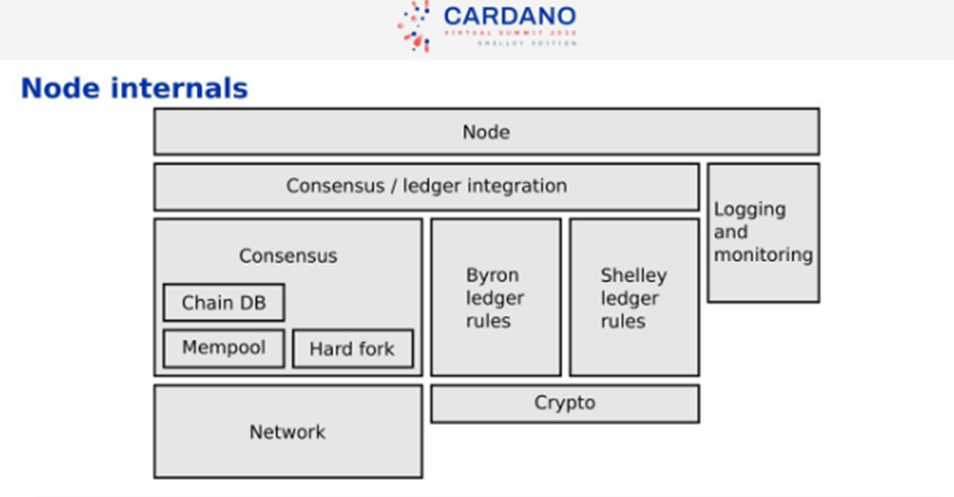
The two large chunks of the functionality are the consensus and the library. Top-level integration has a command line, configuration file, etc. The consensus and ledger don’t depend on each other. For the real Cardano network, we need to do a hard fork from Byron to Shelly. The integration layer selects the composition of the ledger. Ouroborus is the blockchain algorithm. The consensus block has various components like Chain Database, Mempool, and also has the capacity to Hard Fork. The Byron and Ledger rules are sperate from each other. Below that we have the Cryptography Libraries. The Network block is ‘networking which supports the consensus’.
Key challenges
Critical challenges with distributed computation over a network include:
- Delayed Messages
- Corrupt actors, acting maliciously
- Dynamic level of participation (network failures)
- Time-dependent, as it needs coordination to trigger certain events
- Incentive mechanism is not completely aligned to support decentralization
Benefits of Proof of Stake
- A PoS Signature is cheap to create and cheap to verify
- Cost is finely balanced between attacker and defender
- A PoS Signature requires the full ledger state to verify
- Requires interaction between network and consensus concerns
Design Principles
The balance of costs between attackers and defenders is the key problem to solve. Cardano keeps the below design principles in mind
- The protocol is designed by thinking about the worst adversarial condition
- Rely only on local or trusted information. We can not share reputation information very easily
- Minimize difference in memory use between typical and worst case
- Graceful degradation under excess load
3 major examples of design decisions
- Validation should be interweaved with chain relay. Only forward the information that is valid. Don’t use up resources. Prevent bad data from wasting resources. Disconnect from bad peers.
- Stateful Protocols – Long-running sessions (TCP Sessions) are used. There is an opportunity to use a server-side state is an extra tool. “Pull” style protocols avoid getting overloaded.
- A stateful chain-following protocol – Following a forking chain is complicated. A protocol with some server-side state makes it much simpler.
Node Protocols
We have protocols between nodes. And also between nodes and clients. We have chain synchronization used for both nodes to node and node to client. For the client, we do whole blocks. For node to node, we do headers only. We do not have one big protocol. We have 3 separate application-level protocols. All of these run over a single TCP connection. In the local case, we do not need to care about latency. In node to the client, a protocol for querying is expensive to do.
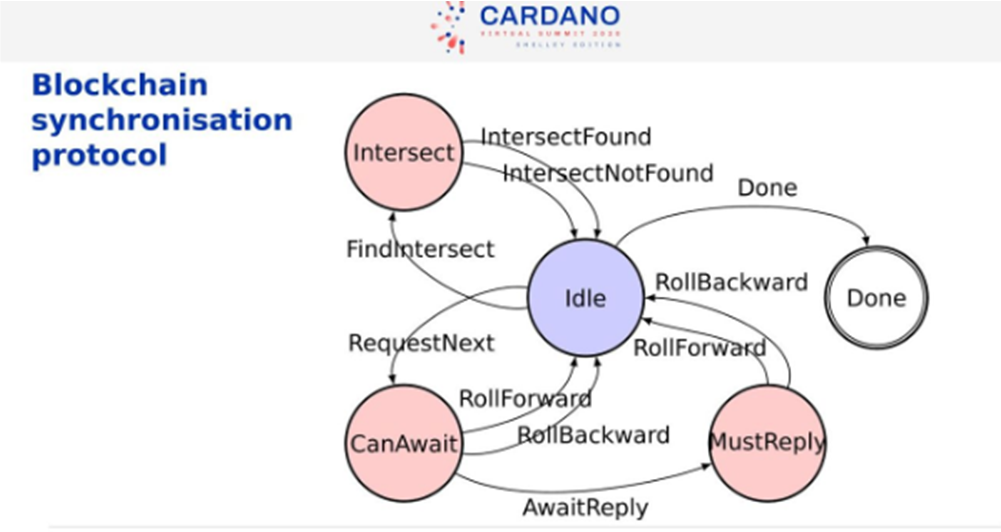
Blockchain synchronization Protocol
Below is a state transition diagram for the main protocol. It is a simple but powerful protocol.
Consensus
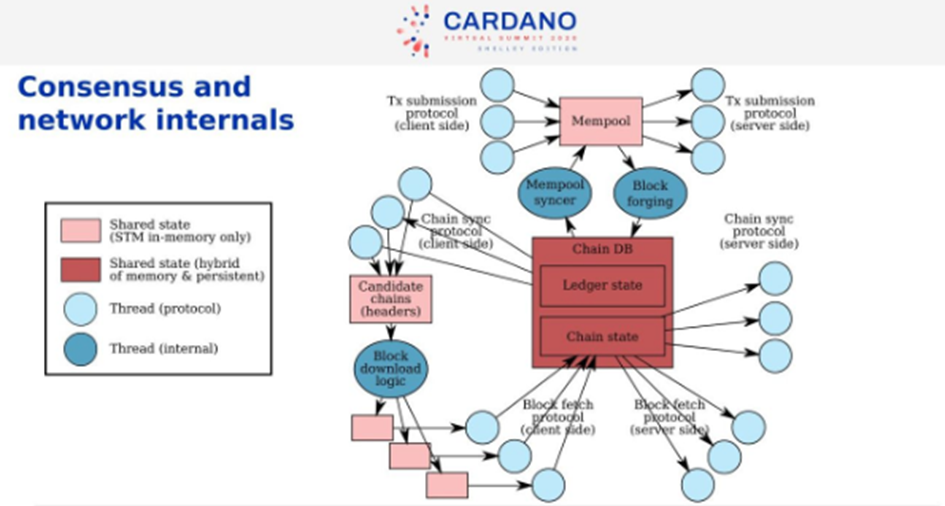
In the middle, we have Chain Database, which includes the chain and the ledger state. The little blue groups are Threads, one per other peers. We have Threads that deal with protocol interaction. The Chain Sync protocol follows the chain of upstream peers. We validate the headers. If it finds invalid ones, it will disconnect. Locally, there are copies of the last blocks.
The Block Download Logic looks at the upstream pair headers and tells us which one is the longest one, which one do I prefer. Then we decide which blocks we download and which peers. We choose the ones that are the best, quick, and fastest.
The Block Fetch Protocol downloads the blocks and adds to the current chain state.
The right-hand side is the downstream peers.
The Mempool is where the transactions coming from the client-side of the protocol are put. The Mempool is continuously revalidated when the chain database changes. Information flows from the Mempool to Chain Database by Block Forging.
Industry Event Sourcing
All the above design decisions lead us to the event sourcing style. We maintain a log of all the changes, essentially the blockchain. Applications process the sequence of changes. We use the DB Sync client to reflect the chain data into an SQL Database.
Consensus Testing
We generated thousands of scenarios. Also, we did a systemic random generation of complicated scenarios. We also generated the most extreme scenarios, where we know you could not achieve consensus. The tests were random but deterministic, all failures can be reproduced. All these uncover bugs that will never be found by traditional means.
Will nodes need to be on separate machines?
Yes. That is primarily for security. Relays are public-facing. You can resist DDOS effectively if you are a bigger target. Several relays mean you have become difficult for a DDOS attack.
Do you guys sit and talk all day?
Yes. That is a very important part of the design. Producing simple solutions is really hard work. This ends up being quicker to implement. Discussions are remarkably effective to produce quality code.
Why do you use a TCP solution?
We rely on our protocol-needs to be Stateful at an application level. It is a whole lot easier to build on top of TCP. It adapts to the available bandwidth. You need TCP, simply because you need to get through all the firewalls etc. We do not plan to do any more changes before Shelley release
In this architecture, where do sidechains sit?
They don’t. They are not in our architecture. We have not properly solved it. There are some papers, but we are not yet happy with the final solution.
Previously, we covered Ouroboros, as explained by IOHK researchers. Stay tuned, we have more updates on what happened in the Cardano Shelley Summit 2020.



{kind=link}